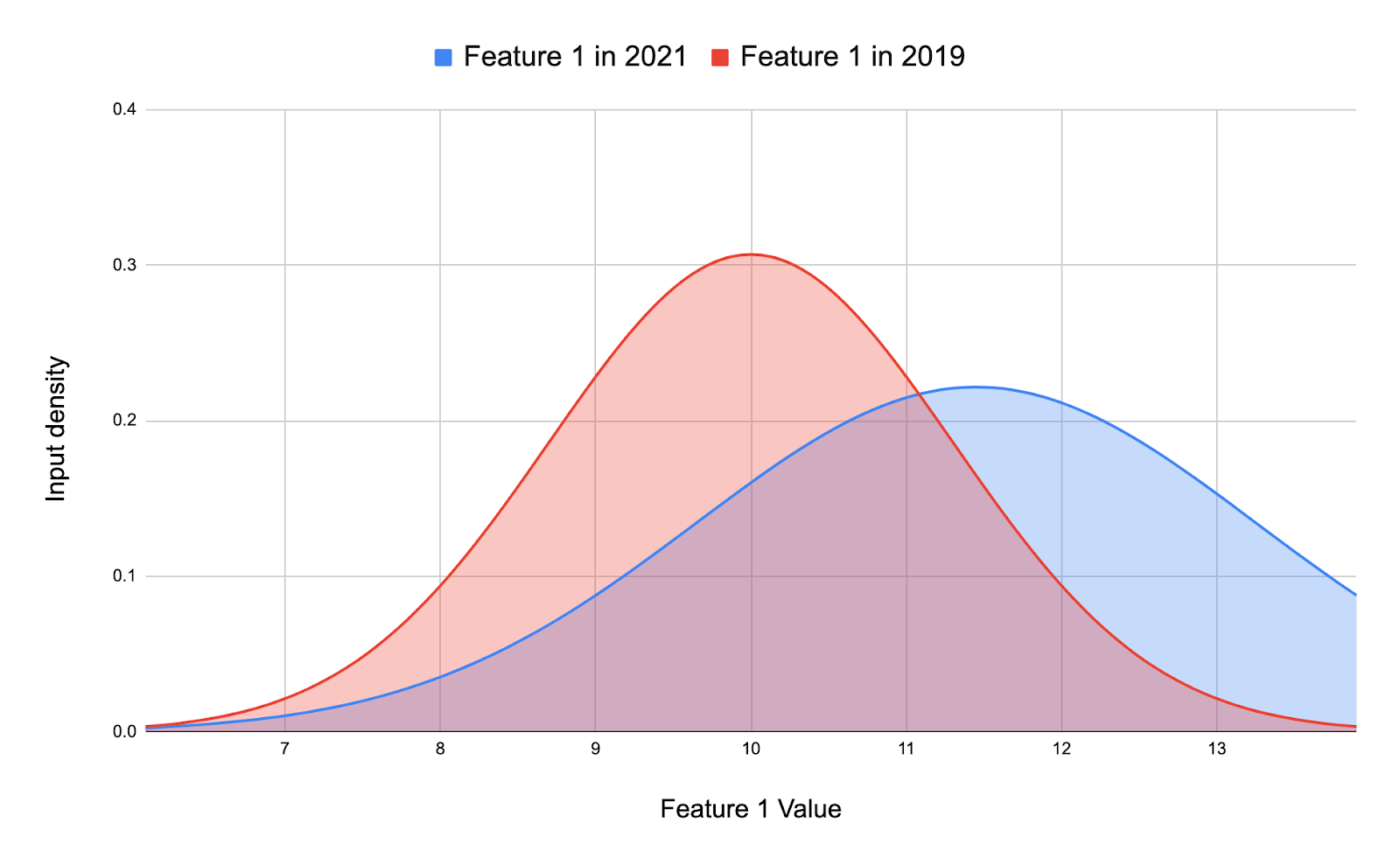
So you’ve developed a model and it has very good performance. Let’s say for simplicity that the performance metric is accuracy and your model has 86% accuracy. But a few months after deployment, turns out your model isn’t doing so well. The performance has dropped to 70%. Or maybe, delays in the project and the model deployment caused the trained model to just sit there for months without being deployed into production. When it finally was deployed, the performance wasn’t great. So does that mean the model you developed back then wasn’t actually good? Not necessarily, “shift happens”, and in this series of posts I’ll talk about how data drift (data shift, get it now) might be behind the degraded performance, the different types of data drift, how to identify data drift, overall model monitoring practices so that these changes don’t catch you off guard and finally how to overcome and fix your model after identifying data drift. This is the first post of a series of posts related to Data Drift and Model Monitoring.
Please see the full article I wrote on medium to learn more about the different types of Data Drift and how they occur. The types of data drift covered include:
- Covariate Shift
- Prior Probability Shift
- Concept Shift